Version control. Git.
Today we will talk about Version Control and Git.
 Image credit: git-scm.com
Image credit: git-scm.com
-
About the version control system
What is a “version control system” and why is it important? A version control system is a system that records changes to a file or set of files over time and allows you to return later to a specific version. For file version control, this book will use the source code of the software as an example, although in fact you can use version control for almost any type of file.
If you are a graphic or web designer and you want to save every version of an image or layout (most likely you will), the version control system (hereinafter referred to as SLE) — just what you need. It allows you to return files to the state they were in before the changes, return the project to its original state, see the changes, see who last changed something and caused the problem, who set the task and when, and much more. Using SLE also means in general that if you have broken something or lost files, you can safely fix everything. In addition to everything, you will get it all without any extra effort.
-
Local version control systems
Many people use copying files to a separate directory as a version control method (perhaps even a directory with a time stamp, if they are smart enough). This approach is very common because of its simplicity, but it is incredibly prone to errors. You can easily forget which directory you are in and accidentally change the wrong file or copy the wrong files that you wanted.
In order to solve this problem, programmers have long ago developed local SLE with a simple database that stores records of all changes in files, thereby monitoring revisions.
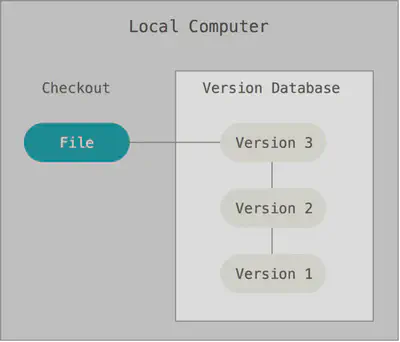
- Centralized version control systems
The next major problem that people face is the need to interact with other developers. In order to deal with it, centralized version control systems (CSKA) were developed. Systems such as CVS, Subversion, and Perforce use a single server containing all versions of files, and a number of clients that receive files from this centralized repository. The use of CSKA has been the standard for many years.
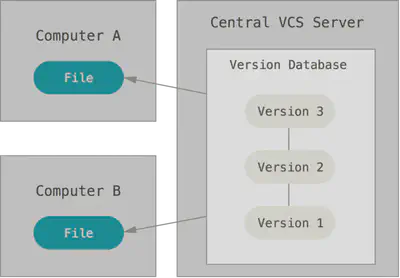
Figure 2. Centralized version control
This approach has many advantages, especially over local SLE. For example, all project developers know to a certain extent what each of them is doing. Administrators have full control over who can do what, and it is much easier to administer the CSCS than to operate local databases on each client.
Despite this, this approach also has serious disadvantages. The most obvious disadvantage is a single point of failure represented by a centralized server. If this server goes down for an hour, then during this time no one will be able to use version control to save the changes they are working on, and no one will be able to share these changes with other developers. If the hard disk on which the central database is stored is damaged, and there are no timely backups, you will lose everything — the entire history of the project, not counting single repository snapshots that have been saved on local developer machines. Local SLE suffer from the same problem: when the entire project history is stored in one place, you risk losing everything.
- Distributed version control systems
This is where distributed Version control systems (RSCs) come into play. In RSKV (such as Git, Mercurial, Bazaar or Darcs), clients do not just download a snapshot of all files (the state of files at a certain point in time) — they completely copy the repository. In this case, if one of the servers through which the developers exchanged data dies, any client repository can be copied to another server to continue working. Each copy of the repository is a complete backup of all data.
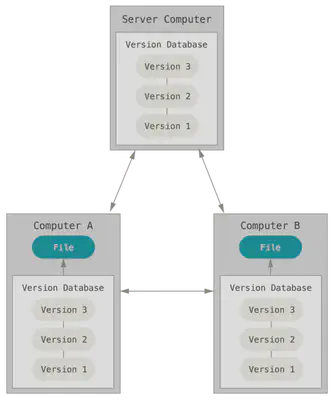
Figure 3. Distributed version control
Moreover, many RSCs can simultaneously interact with several remote repositories, thanks to this you can work with different groups of people using different approaches at the same time within the same project. This allows you to apply several approaches to development at once, for example, hierarchical models, which is completely impossible in centralized systems.
- What is Git?
What is Git, in short? It is very important to understand this part of the material, because if you understand what Git is and the basics of how it works, then it may be much easier for you to use it. While you are learning Git, try to forget everything you know about other SLE, such as Subversion and Perforce. This will allow you to avoid certain problems when using the tool. Git stores and uses information quite differently compared to other systems, even though the user interface is quite similar, and understanding these differences will help you avoid confusion during use.
Snapshots, not differences
The main difference between Git and any other SLE (including Subversion and its brethren) — this is an approach to working with your data. Conceptually, most other systems store information as a list of changes in files. These systems (CVS, Subversion, Perforce, Bazaar, etc.) represent the stored information as a set of files and changes made to each file, over time
Almost all operations are performed locally
For most operations in Git, local files and resources are sufficient — basically, the system does not need any information from other computers on your network. If you are used to CSKA, where most operations suffer from delays due to working with the network, then this aspect of Git will make you think that the gods of speed have endowed Git with untold power. Since the entire history of the project is stored directly on your local disk, most operations seem almost instantaneous.
Git Integrity
In Git, a hash sum is calculated for everything, and only then the saving takes place. In the future, the stored objects are accessed using this hash amount. This means that it is impossible to change the contents of a file or directory without Git knowing about it. This functionality is built into Git at a low level and is an integral part of its philosophy. You will not lose information during its transfer and will not receive a corrupted file without Git’s knowledge.
Three states
Now listen carefully. This is the most important thing to remember about Git if you want the rest of the learning process to go smoothly. Git has three main states in which your files can be located: modified, indexed, and committed:
Modified files include files that have changed, but have not yet been committed.
Indexed is a modified file in its current version, marked for inclusion in the next commit.
Fixed means that the file has already been saved in your local database.
We have come to the three main sections of the Git project: the working copy (working tree), the indexing area (staging area) and the Git directory (Git directory).
Nikita Karmatsky
RUDN student
My research interests include computer games, programming and reading scientific articles.